This is a summary of my presentation titled “DDD in a distributed world” at the DDD Exchange 09 in London.
Distributed systems are not typically a place where domain driven design is applied. Distributed processing projects often start with an overall architecture vision and an idea about a processing model which basically drives the whole thing, including object design if it exists at all. Elaborate object designs are thought of as something that just gets in the way of distribution and performance, so the idea of spending time to apply DDD principles gets rejected in favour of raw throughput and processing power. However, from my experience, some more advanced DDD concepts can significantly improve performance, scalability and throughput of distributed systems when applied correctly.
One of the most important building blocks of DDD that can help in distributed systems are aggregates. Unfortunately, at least judging by the discussions that I’ve had with client teams over the last few years, aggregates seem to be one of the most underrated and underused building blocks of DDD. I’m probably as guilty as anyone else of misusing aggregates and it took me quite a while to grasp the full potential of that concept. But from this perspective I think that getting aggregates just right is key to making a distributed system work and perform as expected.
Aggregates are about units of consistency - not about pointers
Most folks think about aggregates in terms of pointers, such as that objects outside of an aggregate should only reference an aggregate root and not any objects inside the aggregate. Although very useful in general, this rule is not the whole story of aggregates, but that is where most discussions end. Aggregates are also perceived as very technical in nature, almost something that should be left out of the discussion with business experts, similar to repositories or factories. I think that this is a mistake. Aggregates represent a very clear business domain aspect that should definitely be discussed with domain experts. I found it much more important to focus on the fact that an aggregate is a unit of consistency from a business perspective.
We can look at an aggregate from a business perspective as a units of consistency in our problem domain. Something that in a business sense always needs to be perfectly coordinated and consistent, something that is only complete as a whole. Eric Evans calls this a “meaningful whole”, suggesting that an aggregate itself has a meaning separate from the meaning of its parts. As such, it is a genuine business domain concept, not just a technical guideline about references. And in order to find correct aggregate boundaries we shouldn’t be concerned that much about referencing code and class encapsulation. This is more an exercise of identifying business requirements for consistency.
From that perspective, aggregates have a clear impact on processing models and implementation of the system. An aggregate is a natural unit of distribution because we probably need all the information in an aggregate to meaningfully process it. Whenever we send information down the wire, the whole aggregate needs to go. It also means that we need to ensure that all changes to a single aggregate are saved correctly as part of a single transaction. Once we have done it, we genuinely have a meaningful piece of work done. This potentially gives us freedom to work on different aggregates in parallel or in separate transactions.
When these forces are aligned, we’ll get a very nice distributed system design and an implementation that performs nicely. When these forces are in conflict, we should stop and analyse the system instead of just ploughing away with the code. The conflict may come from either the technical or the business perspective but having these concepts explicitly defined gives us a good framework to spot something smelling dirty and fix the problem before it becomes too big. That is why aggregate models provide some great hints about distributed processing.
Hint #1: If you don't aggregate enough, even the fastest computers will spin their wheels in vain
Latency is one of those classical problems of distributed systems. It is a very elusive concepts that an average programmer just ignores, because it seems as a networking issue that should be solved by networking people. I remember a guy who was building his own messaging solution and proudly boasted about its performance, demonstrating it by running both the server and the clients on his machine. When we deployed it properly and put one system in the UK and another one in the States, the whole thing fell over almost instantly.
 Think of it this way: to send an page by post you need to find an envelope, put a stamp on that and put it into a post box. There’s also one less visible step there that most people don’t take into account – walking out of the house and going to the post box. Walking outside to a post box is where the latency kicks in. It’s not something people see integral to the process, but it nevertheless exists. Say you wanted to post a contract that has twenty pages. Doing the whole routine for every single page would instinctively feel wrong and no sane person would do that – we would just put all the pages in a large envelope and stick a single stamp on that, then take all that the post box at once. Yet I find people doing the equivalent of posting each page separately in software over and over again, making the system walk to the post box twenty times instead of once and paying for twenty virtual postage stamps. And this is where aggregates start to kick in. The whole twenty page contract is an aggregate and that very fact that is an aggregate should suggest that it should be shipped together. It is a meaningful whole so whoever needs a page probably needs the entire thing.
Think of it this way: to send an page by post you need to find an envelope, put a stamp on that and put it into a post box. There’s also one less visible step there that most people don’t take into account – walking out of the house and going to the post box. Walking outside to a post box is where the latency kicks in. It’s not something people see integral to the process, but it nevertheless exists. Say you wanted to post a contract that has twenty pages. Doing the whole routine for every single page would instinctively feel wrong and no sane person would do that – we would just put all the pages in a large envelope and stick a single stamp on that, then take all that the post box at once. Yet I find people doing the equivalent of posting each page separately in software over and over again, making the system walk to the post box twenty times instead of once and paying for twenty virtual postage stamps. And this is where aggregates start to kick in. The whole twenty page contract is an aggregate and that very fact that is an aggregate should suggest that it should be shipped together. It is a meaningful whole so whoever needs a page probably needs the entire thing.
So I suggest the first rule to help distributed systems with aggregates: Ship entire aggregates straight away to avoid latency.
Hint #2: If you aggregate too much, baggage becomes a problem
 The second classic problem of distributed systems is serialization performance. Serialization and deserialization are often among the biggest performance hogs in a system as they rely on reflection, IO and traversing complicated object graphs. This is again where aggregates can help, but the issue is a bit more subtle.
The second classic problem of distributed systems is serialization performance. Serialization and deserialization are often among the biggest performance hogs in a system as they rely on reflection, IO and traversing complicated object graphs. This is again where aggregates can help, but the issue is a bit more subtle.
We need to keep an eye out for conflicts between the intended processing model and the business view of aggregates. For example, in a classic account system with accounts and transaction histories, it seems perfectly logical to have the account history as part of the account aggregate.
Say we wanted to process transactions for an account on different machines. Sending huge object graphs over the wire all the time makes no sense technically, so shipping the whole history when we send the account would kill the system performance. There we have a conflict between a business view of an aggregate.
Instead of just ploughing away with the code and breaking the aggregate apart for this one occasion (which would lead to the corruption of the design eventually), I suggest pausing and thinking a bit more about this conflict. This is a very subtle trap. First of all, there are no universal models and the model along with the aggregate structure only works within a particular set of scenarios, so stuffing the account history to be part of the account aggregate may or may not make sense depending on how we are going to use the accounts. When there is a conflict between the processing model that we wanted to implement and the aggregate model suggested by the business, that might point to better ways to design the system.
The rule that the whole aggregate gets shipped together would make us ship the whole history each time we send out account information and makes absolutely no sense. On the other hand, being able to meaningfully operate on just a few pieces of information conflicts with the business definition of the aggregate.
An option would be that the history is not really be part of the account aggregate – maybe it is just a list of domain events that record what happened, or maybe they form part of another statement aggregate. In that case, the model gives us a real argument to talk to the business about statements being something that can now get updated asynchronously as it is not part of the main account aggregate. This is why you get the correct balance but not all the statements on in internet banking applications. Inserting a new transaction record might require locking the sequence generator or a table in some database systems, so it costs a lot. If the transactions can be asynchronously updated then we can significantly reduce locking and improve the system performance. This model gives us distributed processing but clearly points out that the history is not going to be 100% consistent with the balance all the time. It would require a recognition from the domain experts that the history does not belong to the unit of consistency of an account.
On the other hand, if we don’t get the confirmation from the business about that, the fact that all of it has to be part of the same aggregate tells us that distributed processing of a single account is not where we want to go. We need to find a different solution, possibly a distributed master-worker with worker machines owning accounts and the master routing tasks to be processed on the appropriate machine.
So the second rule I’d like to suggest is: If you don’t need it all, it is probably not an aggregate and you can improve performance with asynchronous updates.
Hint #3: If you don't aggregate enough, things are going to be broken just when you need them
 This relationship between synchronous atomic updates and aggregates works both ways. Without properly defined aggregate boundaries in the model, we might actually be breaking up transactions into pieces that do not make sense individually. If there are no aggregate boundaries, there is nothing to tell us what actually is a consistent update from a domain perspective and we’ll probably form transactions around requests. This might lead to a lot of unnecessary code to handle technical “edge cases” which aren’t really business exceptions at all.
This relationship between synchronous atomic updates and aggregates works both ways. Without properly defined aggregate boundaries in the model, we might actually be breaking up transactions into pieces that do not make sense individually. If there are no aggregate boundaries, there is nothing to tell us what actually is a consistent update from a domain perspective and we’ll probably form transactions around requests. This might lead to a lot of unnecessary code to handle technical “edge cases” which aren’t really business exceptions at all.
For example, a trading system might require customer’s credit card details for any meaningful operation. Because of web design constraints, the registration process for customers on the web site might be divided into several steps, where they would first fill in the personal details and then put in the payment details on a separate screen.
If we don’t capture the fact that the payment information are actually part of the customer aggregate then the normal way to implement this would be to form the transactions around requests – posting after each screen. That would allow the system to create customers with no payment information (when they close the browser or just don’t complete the registration). These strange cases will start popping up in reports and we’d have to implement workflows to handle these customers, preventing them from accessing functionality that requires payments etc.
If we do consider both parts a single aggregate, the rule that we should ship entire aggregates (even from the web site to create the customer account), leads to the conclusion that the data should be collected from both screens first and sent at once, instead of sent after each individual screen and processed in the database.
Because aggregates are units of consistency, in order for them to stay consistent we need to keep all steps in an update of an aggregate together. Aggregate updates need to obey the samurai principle: either return successfully or not return at all. Without this, we are opening the doors for data corruption - not in the disk failure sense but in the business sense. The technical edge cases that don’t exist in the business simply go away, so we don’t have to handle them or maintain code to work around them.
Atomicity of transactions fits into aggregates really nicely and this is where transactions also come in. If we think of aggregates as units of consistency, that allows us to design the transactions in our system to work on a single machine as we can ensure that all the information that should be processed synchronously within a transaction resides in a single place. Aggregates are natural atomic parts of transactions.
The third rule I suggest for improving distributed systems is: We should form our transactions around business units of consistency rather than technical requests to avoid data corruption and simplify processing. The entire aggregate should be processed synchronously within a transaction.
Hint #4: If you aggregate the wrong things, deadlocks galore
 Locking resources in distributed systems is also one of those invisible issues that can just kill you if you don’t get it right. Distributed systems are typically built to process more than a single machine can – to increase the overall system throughput. Yet if critical resources are locked too much and processes often have to wait for other processes to release those locks, spanning to multiple machines might actually give you worse performance.
Locking resources in distributed systems is also one of those invisible issues that can just kill you if you don’t get it right. Distributed systems are typically built to process more than a single machine can – to increase the overall system throughput. Yet if critical resources are locked too much and processes often have to wait for other processes to release those locks, spanning to multiple machines might actually give you worse performance.
One example that we had in a recent DDD Immersion workshop, changed a bit to protect the innocent, is a scheduling system that involves event organisers and events. The unit of consistency in a business sense was an event organiser, so that was the aggregate by design. At some point, the system was integrated with an external notification source with messages about changes to events. A message might contain updates for hundreds of events for different organisers, postponing, rescheduling etc. The business wanted a notification message to be processed within a single transaction, regardless of what it contains. After the change, the system performance seriously deteriorated as a single notification message was locking hundreds of organiser objects.
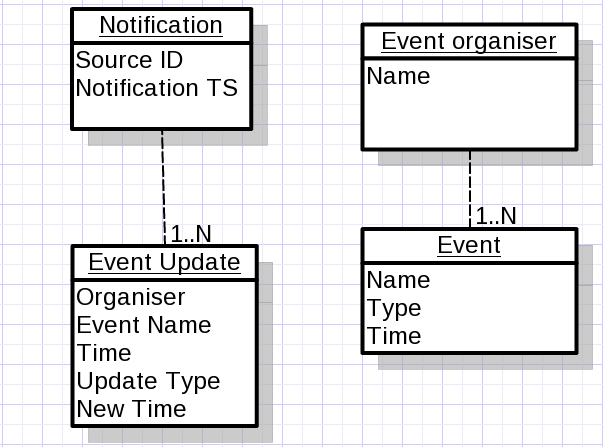
This is another example of the processing model conflicting with the business model of aggregates. If the organiser and its events are units of consistency, then we should be able to update one organiser entirely and not update the others and the system would still be consistent. If this is confirmed by the business (which is more likely than not), then we have a good case against the requirement to process the entire message in a single transaction. We can take the message, store it and commit, then break it apart into chunks related to individual organisers in another transaction and commit that, and then process individual chunks in separate transactions. This model also allows us to process individual organisers in parallel so the business will probably see the final effect sooner than with a single transaction anyway.
The fourth rule coming out of this is : When locking, lock aggregate roots. Challenge requests to lock more than one at the same time.
Reinforcing ideas
Aggregates are a curious pattern as they clearly have both a business domain and a technical side. These two sides of aggregates confirm and reinforce each-other. That is what makes them so useful for modelling and designing distributed systems. Once we know what makes a conceptual unit of consistency, we have defined the clusters that need to travel down the wire or be processed as a single unit. If the required processing model contradicts that, then we need to revisit the aggregate definitions or the processing model.
Once we draw the lines of the aggregates and think of them primarily as units of consistency we can have a meaningful discussion on what implementation model suits our required set of scenarios. Aggregates are natural choices for some of the most tricky issues of distributed systems, including locks, transactions, asynchronous processing, serialization and latency.
If we want one but not the other that probably means that we don’t have the correct aggregates boundary, or that we have unrealistic expectations. And spotting this early on is one of the greatest powers of aggregates as a concept – we don’t have to burn our fingers by spending months developing something that simply is not going to perform or satisfy requirements.


