Speaking at the DDD exchange conference today, Greg Young said that doing doing domain driven design is impossible with a classic three layer architecture where DTOs are being shared across layers. He then presented CQRS and Event Sourcing, which according to him provide a much better way to design complex systems.
“We need to start capturing the intent of the user. Our domain is focused on behaviours. Users should send back commands, not DTOs. The server needs to be told to do something.”, said Young, advising developers not to use editable data grids in user interface, because they are data oriented. Users should specify the intent, not edit data, said he.
“Actually figuring out what your users do and why they do it will cost money. But once you have done it, it will give you a better architecture and keep you at the same cost – or much much lower. Even at the same cost, we can get a lot of benefit.”, said Young, and suggested CQRS and Event Sourcing as the key patterns to support that.
CQRS
CQRS is based on command-query separation by Bertrand Meyer but evolved. It fundamentally requires splitting apart queries (read operations) and commands (transactions). “Treating them as separate concepts forces us to think that there are different needs for different sides”, said Young.
When we build up DTOs, we have a structural view of our data. When we process a transaction, we have a much more behavioural view. The conceptual structures are actually using completely different boundaries in these situations. So teams often come up with a half-way answer, which leads to a system that is neither behaviourally or structurally optimal. Young said that CQRS enables us not to make these trade-off s any more.
Instead of having a domain layer, we can have a thin read layer for DTOs for queries. This makes it a lot easier to optimise queries compared to using O/R mapping systems. The only knowledge people need to have to write efficient queries is a data model – not the O/R mapping technology, domain models and so on.
Separating out the reads also cleans up a lot of things in the domain layer. The repositories no longer have lots of different read methods, but only those required for particular domain. We don’t have setters on domain objects – they become purely behavioural. “Domain objects are not property buckets, they expose behaviour. We can specialise our domain layer to process transactions. The code will be clearer and the aggregate boundaries will be a lot stronger”, said Young.
Event Sourcing
Once commands and queries are separated, we can look at whether we need to use the same data source at all. When the same data source is used for transaction processing and querying, the third relational normal form is often used for both things. This requires teams to create complex queries. Splitting data sources would enable us to specialise the query data source for reading, having a first normal form model. The two data sources can then be synchronised.
To avoid inconsistency caused by this synchronisation, we need to build from one source of truth. A good option is to use domain events – notifications about what happened as the result of commands being processed.
The data model for processing transactions can also be write-only. “This is how the business thinks about changes”, said Young, “You can’t refuse to record something that happened”. We can take this even further and not have the current state of the system in the transactional storage. Understanding this enables us to restructure the transactional processing data model to just accept results of command processing. If we unify the models for transaction processing and storage, this cuts down the cost of development and maintenance.
Recording events that resulted from transactions ensures that we don’t lose any information but we can still recreate the current state when needed. This makes auditing trivial and enables a number of other things, such as replay the state of system at any time to troubleshoot or test and extracting analytics in the future that we haven’t thought about while developing the system.
Having a system structured like this requires the domain model to only to know about events. This simplifies testing – both checking for expected results and unintended consequences. Testing events would check both at the same time – any unintended change would generate more events. Integration with other systems also becomes a lot easier, according to Young, because this naturally flows around events and commands.
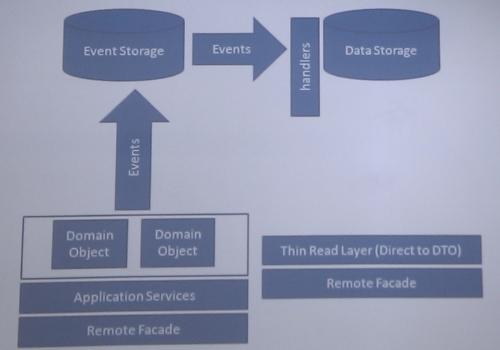
The event storage can also act as a queue to feed the query storage, and essentially require only a single transactional commit from the system while processing commands. This makes the system even more performant.
Related post: Two data streams for a happy web site


