The long term benefits of agile acceptance testing come from living documentation -– a description of the system functionality which is reliable, easily accessible and much easier to read and understand than the code. In order to be effective as live specification, acceptance tests have to be written in a way that enables others to pick them up months or even years later and easily understand what they do, why they are there and what they describe. Here are some simple heuristics that will help you measure and improve your tests to make them better as a live specification.
The five most important things to think about are:
- It needs to be self explanatory
- It needs to be focused
- It needs to be a specification, not a script
- It needs to be in domain language
- It needs to be about business functionality, not about software design
Here is a really good example:
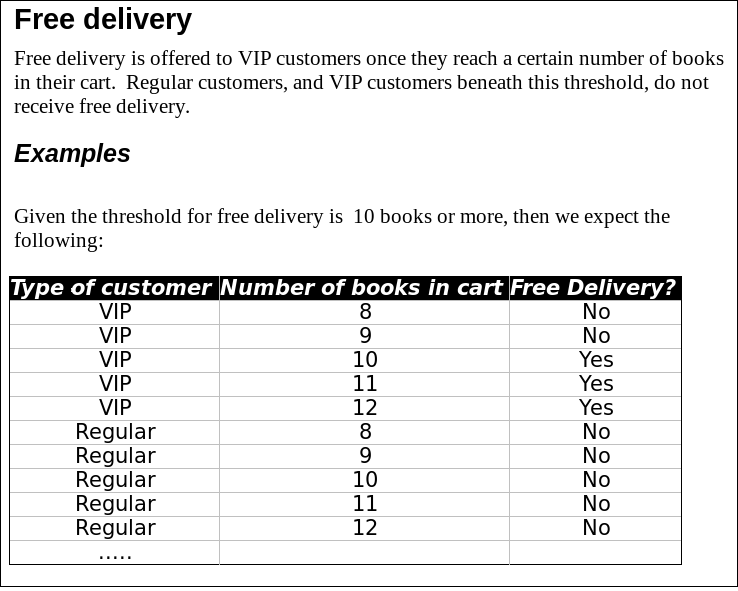
It has all the elements listed above. Whenever I’ve shown it to people in the workshops, I did not have to use a single word to explain it. The title and the introductory paragraph explain the structure of the test data enough that readers don’t need to work back from the data to understand the rule. But the examples are there to make it actually testable and explain the behaviour in edge cases. It is focused on a very particular rule of free delivery availability, does not explain how the books are purchased but just what the available delivery mechanism is, and does not try to talk about any implementation specifics.
Here is a really bad example (taken from the old Fitnesse user guide)

This test has so many bad things in it that it is actually a good example to demonstrate what happens when people don’t take care about writing good tests.
First of all, although it has a title and some text around the tables to seemingly explain what’s going on, the effect of that is marginal. Why is this test “simple”, and what exactly in payroll is it checking? It fails straight away on the self-explanatory litmus-test.
Second, it’s not really clear what this test is checking. We need to work backwards. It seems to verify that the cheques are printed with unique numbers, starting from the next available number that’s configurable in the system. It also seems to validate the data printed on each cheque. And that there is one cheque printed per employee (I’ll come back to this later).
There is a lot of seemingly incidental complexity there - names and addresses aren’t really used anywhere in the test apart from setting up the employees. There are some database IDs there which are completely irrelevant for the business rules, but they are used to match up employees and the paycheck inspector.
Paycheck inspector is obviously an invented thing just for testing. No company is going to have Peter Sellers in a Clouseau outfit inspecting cheques as they go out. If you have enough employees to have to print cheques, you don’t want to inspect them manually. That’s what this test is about, anyway.
There is also a very interesting issue of those blank cells in the assertion part of the test, and the two Paycheck inspector tables which seem unrelated. Blank cells in Fitnesse are used to print test results for debugging and troubleshooting, they don’t check anything. So this is an automated test that a human has to look over — pretty much defeating the purpose of automation. Blank cells are typically a sign of instability in tests (more on this a bit later) and they are often a signal that you’re missing something - either testing in the wrong place or missing a rule that would help make the system process repeatable and testable.
The language is inconsistent, which makes it hard to make a connection between inputs and outputs at first. What is the 1001 value in the table below? The column header tells us that it is a number - well thanks for that, I though it was a sausage. There is a “cheque number” above, but what kind of a cheque number is that? What is the relationship between these two things?
So this test is very very bad.
Presuming that the addresses are there because cheques are printed as part of a statement with an address ready for automated envelope packaging, this test fails to check at least one very important thing (and I’ll come back to this later as well): that the right people got paid the right amounts. If the first person got both cheques, this test would happily pass. If they both got each-others salaries, this test would pass. If a date far in the future was printed on the cheque, our employees might not be able to cash it in but the test would still pass. The reason these cells are blank is because there is another hidden rule there: ordering of cheques coming out. There is nothing specifying that. So a technical workaround for a functional gap is to create a test that gives us loads of false positives.
Is this test checking one thing or many things? Without the context information it’s hard to tell. If the cheque printing system is used for anything else, I’d pull out the fact that cheque numbers are unique and start from a configured number into a separate page. If we only ever print salary cheques, it’s probably part of a single thing (salary cheque printing).
Now, let’s clean it up. Let’s try to work back and drop all the incidental stuff. Let’s use a nice descriptive title, such as “Payroll Cheque Printing”. And let’s add a paragraph that explains the structure of the test.
A cheque has the payee name, amount, payment date. A cheque does not have a name and a salary. If the cheque is printed on a statement, it also has an address that will be used for automatic envelope packaging. A combination of a name and address should be enough for us to match the employee with his cheque — we don’t really need the database IDs. We can make the system more testable by agreeing on an ordering rule, whatever it is. For example, alphabetic by name.
Let’s also pull the context to the start of the test. Our context is the payroll date and the next available cheque number, along with employee salary data. Let’s make it explicit what the number is for, so that the readers don’t have to figure this out for themselves in the future. We can also make this block stick out visually to show that it is about the context.
The action that gets kicked off doesn’t necessarily need to be listed in the test. A payroll run can be executed implicitly by the table that checks payroll results. This is an example of focusing on what’s being tested instead of how it is being checked. There is no need to have a separate step that says “Next we pay them”.
Let’s also rename that paycheck inspector to something that makes more sense. Because we want whoever automates this to ensure that we check for all cheques printed, let’s put that in the header. Otherwise, someone might use subset matching and the system might print every cheque twice and we won’t notice.
And here is the cleaned version.
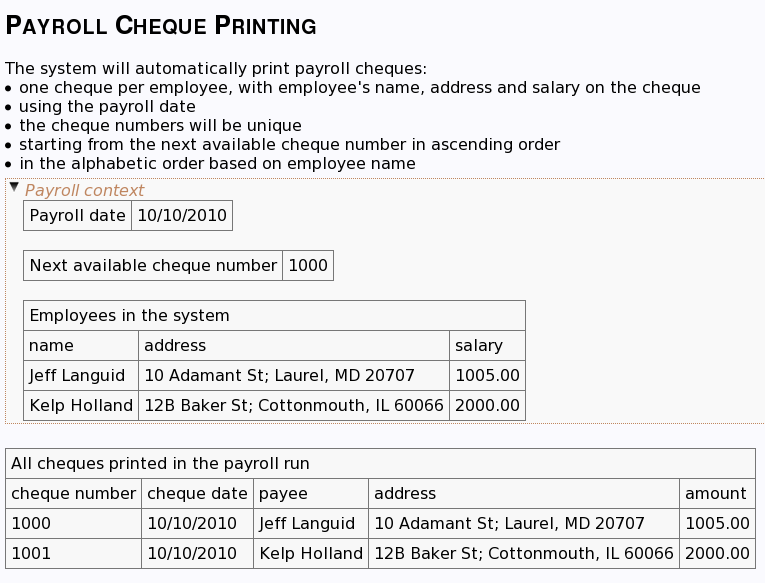
Much easier to understand, without all that incidental stuff. And now comes the punchline. When we look at the test like this, without database IDs, without all the unnecessary clutter, we can have a nice shot at answering the question “Are we missing something?”. What are the edge cases that might break this? We don’t really need to ensure validity of employee data, hopefully that’s done in another part of the system. But is there any kind of valid employee data that would be an edge case for this test - can we play with the numbers to make this illogical in some way?
An obvious answer to that is - what happens if an employee has a salary of 0? Do we still print the cheque? The rule as we described it says “One cheque per employee” - so any employees that have been fired years ago and no longer receive salaries would still get cheques printed, with zeroes on them. We could then have a discussion with the business on making this rule stronger and ensuring that cheques don’t go out when they don’t need to do.
FitNesse gets a lot of bad reputation because of this kind of broken tests. Concordion was built as an answer. Some people at my recent workshop on this example pointed out that Given-When-Then structure of Cucumber would be better at preventing some of these problems. I don’t think so. It’s not about the tools - people can do this kind of bad test design with any tool, and likewise they could do nice and clean tests with FitNesse. I guess the fact that the basic examples coming with FitNesse are so bad doesn’t help, but the problem is not in the tool. It’s about the process and effort put into making the tests easy to understand. The funny thing is it doesn’t take a lot more effort to make the test nice and clean, but it brings a lot more value that way.


