Value objects are one of the basic building blocks of object domain driven design. The pattern makes manipulating objects very easy and is very easy to understand. Yet often I see teams with a strong preference to entities, making clean design harder to sustain and system much harder to write and more error-prone on the end. In most cases, this oversupply of entities comes from the fact that critical business data has to be persisted and by persisting the object we give it many traits of an entity. In my opinion, this is jumping to conclusions too quickly. I prefer values over entities because of all the management advantages that they have. Persistence is not an excuse to turn everything to entities. In this post, I’ll show you several tricks how you can persist object and still keep all the benefits of value objects.
To keep this practical, I’ll use a classic cargo example from the blue book – cargo is an entity here, itinerary and legs are value objects.
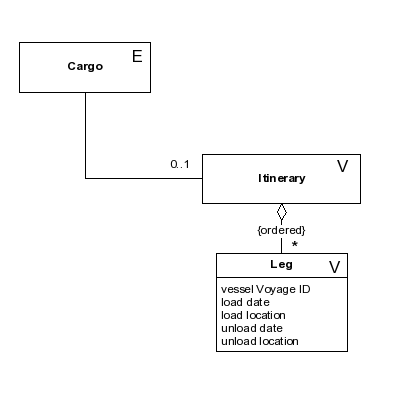
All three need to be persisted. By default, if you apply the rules of relational normal forms and classic ORM mapping of one class to one table, you get three different tables.
Option 1: three separate tables, normalised
And this is where the problem lies. Efficient database access often requires us to have a primary key so what could be the primary keys for itineraries and legs? It can’t be a group of attributes as they are not guaranteed to be unique. It shouldn’t be all the attributes together as well because database rows are inherently mutable. Value object pattern explicitly allows you to replace a leg in an itinerary without fearing that you’ll unknowingly change the itinerary of a completely unrelated cargo. So the remaining solution is to have an auto-generated surrogate primary key, effectively making this value object an entity with an ID.
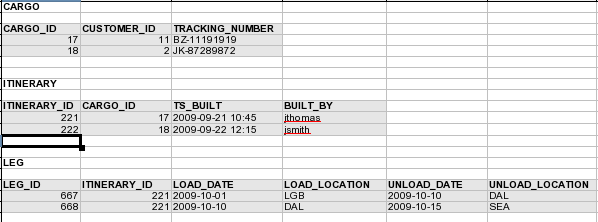
But the fact that this has a database ID does not necessarily mean that we have to expose it in a Java or C# class or make the object mutable. The storage ID can be regarded as a purely technical address locator, very similar to the object ID in Java/C#, which effectively represents the memory location. The technical framework (JRE or CLR) uses this technical identifier to manipulate objects but class users typically don’t see or use this. You can encapsulate a technical ID that helps you manipulate the object in the database behind a public class interface so that class users don’t see it. Hibernate can also map a private field to a database identifier for you, and even work without you declaring an identifier at all (although that is not recommended).
This gives you a perception of a value object in object code, but it requires very careful management and makes the system quite error-prone. Using copy-construction through a public interface will disconnect the object from its technical ID so you might get more than one database row for the same thing. Also, not using a value any more doesn’t guarantee that it will be cleaned up from the database, so this approach might lead to some stale data in the database. With simple components (eg itinerary) you’ll get an error back if two rows exist where you expected one, but for collections (eg legs) it is going to be a lot more problematic. We expect the collection to come out of the database so if Hibernate doesn’t clean things up properly we’ll get both the old and the new elements next time the collection is loaded. As Hibernate manages collections with its specific implementations, adding or removing an element is fine but replacing the whole collection can lead to serious problems.
It probably isn’t the most efficient way to store value objects either.
Relational normal forms are introduced so that we can easily query, merge and update data, but that is not necessarily what we want here. Especially the global update.
Option 2: denormalised, relevant hierarchy
Itinerary doesn’t make sense without a cargo, at least the persistent one does not. And there is only one active itinerary for a cargo, so instead of having a separate table of itinerary properties we could just merge them into the cargo table. Legs could be kept separate, as there many legs per itinerary, but we could use the cargo identifier and the leg index as a composite primary key.
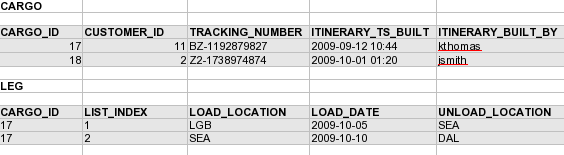
This can still be managed easily by an ORM. Hibernate has a concept of an embeddable component that doesn’t have an identity separate from the enclosing entity. Itinerary in this case is an example of that. As for the legs, you can easily map that into a collection of embeddable items and use exactly the indexing strategy that we chose here. See Hibernate documentation on components for more information on how to map this exactly. With Hibernate annotations you can use one-to-many join table without the entity on the other end to actually map this. In any case, it is easily doable and keeps your Java or .NET objects clean, although the database model gets a bit dirty.
This approach can be very tricky to implement properly with distributed systems. Hibernate will automatically keep track of objects added to and removed from collections and can cascade updates to the database, but this is done using Hibernate-specific subclasses for sets and lists. Copy the elements to a normal list and most of the functionality will be lost. So this approach requires less care and overhead than the first because the simple components (eg itinerary) are true value objects, but collections can still cause stale data and problems.
Option 3: clob/blob/string representation next to entities
Another option is to throw away the relational model altogether and go for an alternative approach, storing the entire object graph of objects in a column in the cargo. This approach has a distinct advantage of much more efficient database loading, as it avoids any hierarchical queries to retrieve legs and significantly reduces row locking when updating legs (this is very important for MySQL or SQL Server users where the entire leg table might get locked although you don’t expect it). There are many ways this can be accomplished – binary serialization is the simplest but least flexible. Binary format isn’t the most readable so the data in the database will be effectively useless until it is loaded in memory, so any other tools using the same data store such as business intelligence or data warehousing will be lost. There are generic XML serialization libraries such as Thoughtworks Xstream which can pick up a class and dump it into XML but I’ve burnt my fingers with this approach so I wouldn’t recommend it. As with the binary form, Xstream serialization is bound to a particular class version so if the class changes significantly in the future (eg renamed or removed fields), you simply won’t be able to load any older versions. Generic reflection based serialization also tends to be a real performance hog.
A good option here to store the value in a human readable string that allows you to convert both ways. One recent example I had was a spreadsheet-like price management system where traders would define variables and formulas for fields. The hierarchy was like this:
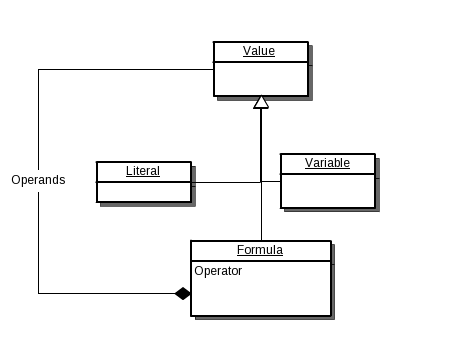
Formula is a typical value here. Storing things in a relational normal form would overcomplicate things so much that I don’t know where to start. A formula can consist of other formulas so we have a hierarchical recursive dependency with symbols, operators etc all participating so elements could span and be connected with different tables. In short, loading and updating a formula like this would cause a world of pain for a database, even the ones that can do hierarchical queries. Yet when you look at it from the outside, traders enter formulas by typing text into a cell, which then gets parsed and transformed in a complicated object graph. Why not put in just a bit more effort and make this conversion two-way, and then store a text representation of the formula in the database? Sometimes there is a natural string representation of a whole value object graph, sometimes you have to be a bit inventive, but it pays off big on the end.
For example, we could store the itinerary as a list of legs, one per line, with tabs between leg attributes. Or there might be a genuine business string representation of a leg, such as LGB-SEA. Watch out for these in your meetings with business domain experts.

A conversion such as this one could run pretty quickly and gives you probably more optimised storage and much more readable data, not mentioning avoiding class loading problems. And, as there is only one row to load, data loading works much quicker and we don’t have to worry about the dreaded N+1 problem of object traversal.
So which of these two options is better? Well that depends on the context, as always. If you don’t need to query efficiently for individual items in the list, then you don’t really get any benefits of data normalisation, so the last option is probably the best. If you do need to search efficiently for cargoes with a particular leg or moving through a particular point, then the second option is much better. With the third approach we also lose the chance for database to enforce relational integrity. Again, this might not be always required and even if it is, we can implement it in the application layer.
Another interesting solution is a hybrid approach where data is stored in both forms. When loading objects, we load it only from the primary table and construct the object graph from a string. When searching, we query the normalised table. This hybrid approach gives you great database performance for reading and searching while complicating updates just a bit. It introduces data redundancy, but the benefits outweigh the costs in most cases. You can even optimise normalised data for the particular queries that you’ll run. For example, I worked on a i18n project for a web site where we used phrases as domain concepts (as it makes no sense to translate words without a context). But we also broke down phrases into individual words for querying and updated both tables when saving a phrase. This hybrid approach can work really well and you can take it even further and retrieve value objects from a cache or internalise them for memory or performance optimisation. Hibernate Search uses the same idea and maintains a full-text search index automatically for you.
As a summary, here's a few things to remember when persisting value objects
- Not everything that has a database ID is an entity
- Not everything has to come from the database
- Not everything has to be persisted and restored in the same form
- Not everything has to be persisted and restored


