
Problems: Story is too big to split and estimate; business users don’t accept any breakdown proposed by the delivery team; team is inexperienced and thinks about technical splitting only;new project starts and no simple starting stories can be found
Solution: User Story Hamburger
I’ve evolved a new technique for splitting user stories over the last few months shamelessly stealing repurposing Jeff Patton’s User Story Mapping and ideas described by Craig Larman and Bas Vodde in Practices for Scaling Lean & Agile Development. I think it works particularly well in situations where a team cannot find a good way to break things down and is insisting on technical divisions. It has the visual playful aspect similar to innovation games and it’s easy to remember. I call it the User Story Hamburger.
Inexperienced teams often can’t get their heads around splitting stories into smaller stories that still deliver business value. But they will happily break a story down into technical workflow or component tasks. I like the idea of User Story Maps which show the big picture under a breakdown of a business workflow. We can do the same on a much lower level, for tasks making up a user story, keeping the team in their comfort zone. Then we use this breakdown to identify different levels of quality for each step, and create vertical slices to identify smaller deliverables. Here is how to create the hamburger:
Step 1: Identify tasks
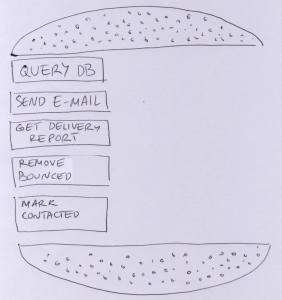
As a group, identify technical steps that would be involved in implementing a story on a high level. Breaking it down into technical/component workflow is OK. The tasks become layers in a hamburger bun - meat, lettuce, tomato, cheese - throw in some bacon for fun as well.
For example, if we’re working on a story to contact dormant customers by e-mail, the steps might be: query db for dormant customers; send e-mail to customers; retrieve delivery report; remove bounced addresses from the system; mark non-bounced as ‘recently contacted’.
Step 2: Identify options for tasks
Split the team into several small groups and ask them to define quality for each task, or what would make a particular task good. Then they should write down several options on different levels of quality on post-it notes.
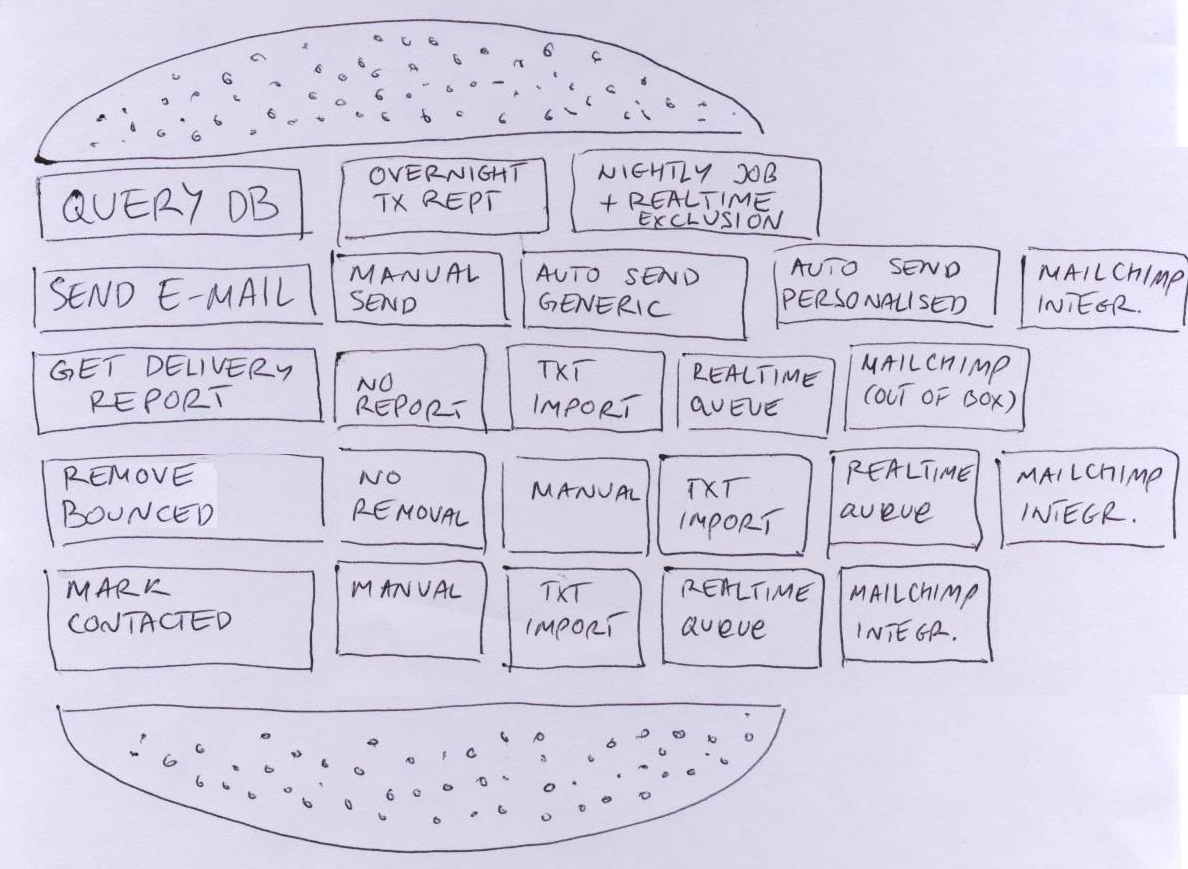
For example, speed of execution and accuracy of results might be a measure of quality for database query for dormant customers. Two possible options could be to make a slow and relatively inaccurate query on all customers compared with overnight transaction reports, which won’t pick up intraday changes. Another option to increase accuracy would be to have a nightly job making customers dormant and remove the dormant mark on every transaction, which would enable us to be 100% accurate and faster. The first option would work only if we send e-mails once a month, the second would work at any time.
Another example might be the volume we can send, the content personalisation and spam-regulation compliance for sending e-mail. We have an option of sending things manually, slow and low-volume. Second option is to use an automated process and send generic e-mails, with a manual unsubscribe process. A third option would be to use an automated process and send personalised e-mails, with manual unsubscribing. The fourth option would be to send personalised e-mail automatically and enable people to unsubscribe automatically. Yet another option would be integrating with a third party service that does all that.
Step 3: Combine results
Create a single hamburger on a big board. Ask representatives from each team to bring post-it notes and fill in the layers of your hamburger, briefly introducing what each note it. Identify duplicates and throw them away. Align task options from left to right based on the level of quality.
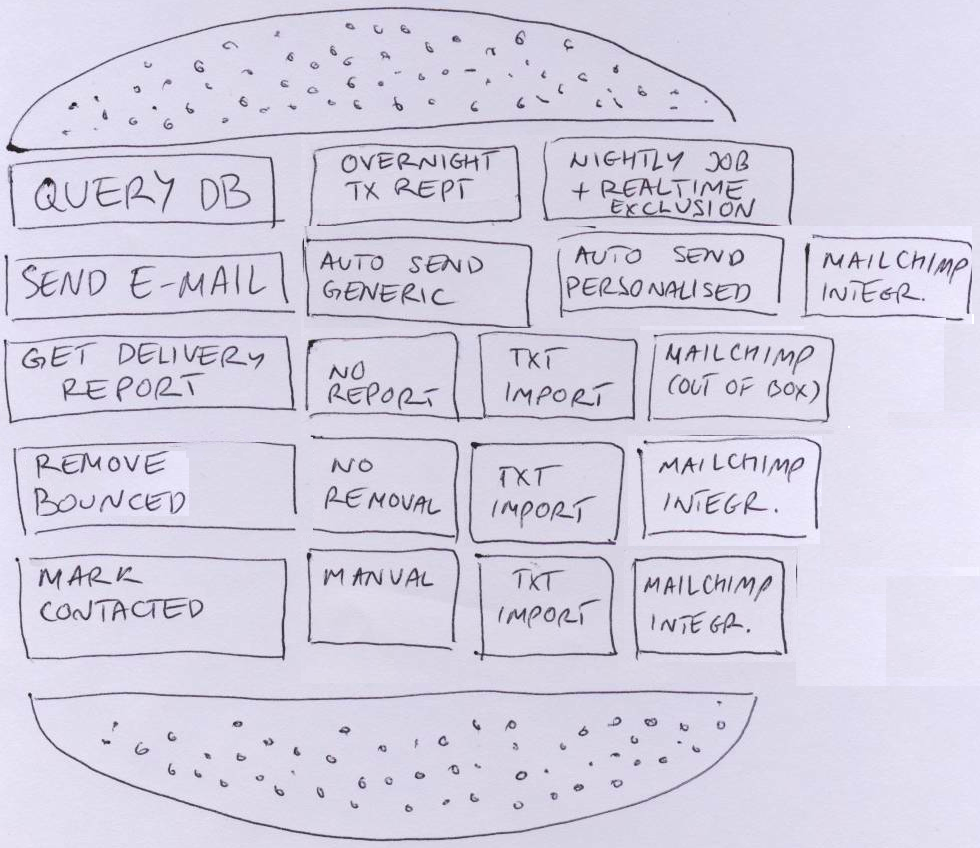
Step 4: Trim the hamburger
As a group, go through tasks and compare the lowest quality options with things next to them, based on how difficult it would roughly be to implement each option. Mark that information on the post-its. It might be worth breaking things down into relatively same-size technical tasks to do some simple comparisons. Think about throwing away lower quality items that would take more or less the same to implement as a higher quality option.
Also decide what is the maximum needed level of quality for each task. For example, intra-day bounced e-mail removal won’t really bring much more value than overnight bounced e-mail removal. Take items over the line out - that’s what will be left in the box after you eat the hamburger.
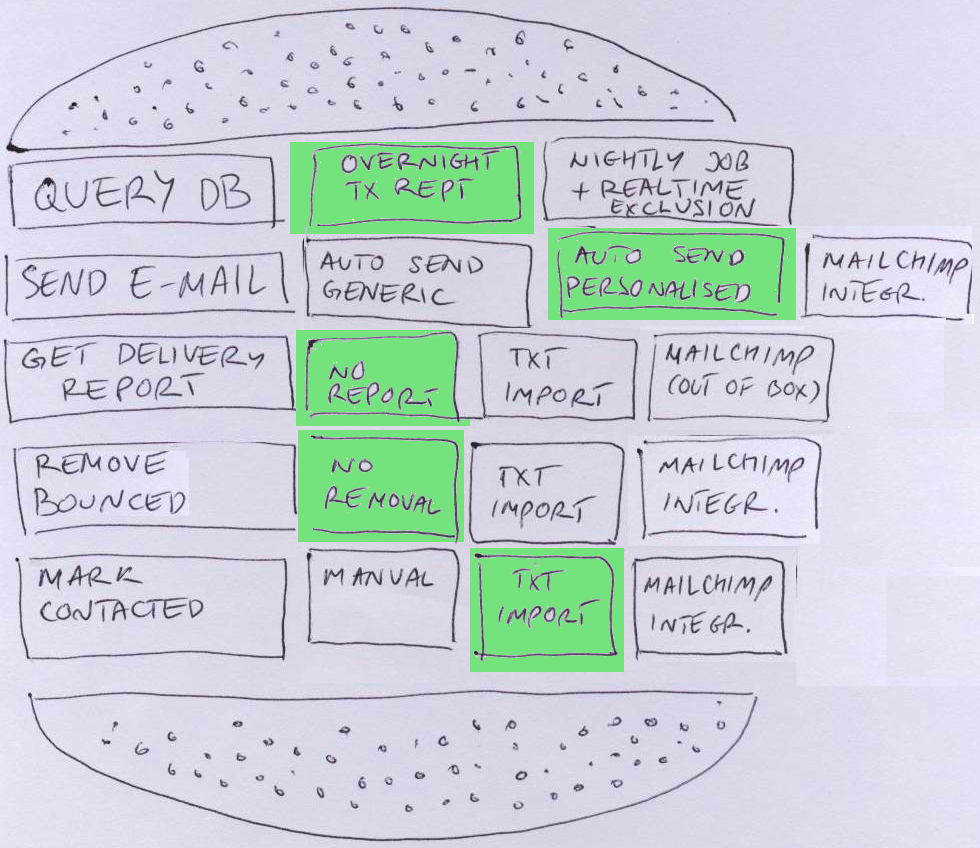
Step 5: Take the first bite
Now that you have a hamburger, decide how deep you’ll take the first bite. Discuss what is the minimum acceptable level of quality for each step. For example, manual sending might not be acceptable at all, because of the low volume. But sending e-mail once a month might be acceptable. If the lowest quality option is more-less the same size as the higher quality one, you might go deeper straight away. For example, sending generic e-mail with manual unsubscribing might be more or less the same effort as integrating with Mailchimp. On the other hand, a fast realtime update of customer activity might be much more difficult than a on-demand slow database query. For some steps, eg removing bounced addresses, doing nothing might be a valid level of quality initially.
Step 6: Take another bite... and continue
From there on, any further bite should provide more quality, regardless of what you add. Eg implementing initial bounced e-mail removal enhances the quality. So does more frequent e-mail sending. Use complexity comparisons between tasks to decide how deep you want to take further bites.
This method works very nicely because it is visual, and it gets people thinking about alternatives while still staying in their comfort zone. It also works nicely with ‘bite-size chunks’ analogies. And you can easily explain why releasing just a technical task doesn’t make sense because no sane person would eat only the lettuce. On a final note, make sure not to do this while people are hungry.



{kind=link}